C8: Analyse de variance à un facteur
Section 1. « un coup de dé jamais n’abolira le hasard »
Une façon simple de sonder une question est de monter une expérience dans laquelle nous contrastons une situation avec un traitement vs. une situation neutre. Par exemple, nous pouvons étudier la dextérité manuelle lorsque les participants utilisent leur main dominante (la droite pour beaucoup) et lorsqu’ils utilisent l’autre main. Cependant, il existe beaucoup de situations expérimentales qui sont graduées. Par exemple, nous pouvons examiner l’effet de l’alcool dans le sang sur la dextérité manuelle. Or, la dose d’alcool peut prendre plusieurs valeurs (de 0 à 0.2 mg/l). Le chercheur risque de ruiner son expérience s’il choisi un dosage trop faible ou trop fort. De plus, s’il obtient un décrément dans la dextérité pour un dosage particulier, disons .08, qu’en est-il à .04? Qui nous dit que la dextérité ne revient pas à la normale passé .08? Pour des raisons de généralisation, le chercheur a tout intérêt à tester plusieurs dosages.
Une expérience à deux groupes indique seulement la présence ou l’absence d’un effet du traitement. Cependant, une expérience dont le plan comprend plus de deux groupes donnera une information plus complète et plus détaillée de la relation entre les divers niveaux de la variable indépendante et la variable dépendante. Souvent, un chercheur qui désire identifier les mécanismes ou les processus sous-jacents à un phénomène particulier doit augmenter le nombre de traitements ou le nombre de niveaux que le traitement peut prendre, et ce, dans une seule expérience.
Le problème est que le test t devient inutile. Supposons, par exemple, que nous voulions évaluer l’effet de 5 doses différentes sur le comportement des dépressifs. En utilisant des tests t, nous devrions comparer le dosage 1 avec le dosage 2, le dosage 1 avec le dosage 3, … le dosage 4 avec le dosage 5. Il faudrait alors procéder à ![]() comparaisons, soit 10 dans ce cas-ci, ce qui implique un nombre considérable de calculs. D’autre part, toutes ces comparaisons ne sont pas indépendantes puisqu’on devra utiliser un même ensemble de données au niveau de plus d’une comparaison. Ceci pose un problème car le nombre de fausses alarmes (erreur a) s’accroît. En effet, si Pr(erreur α) = 5% pour une comparaison, la probabilité de commettre au moins une erreur a lorsque nous effectuons N =
comparaisons, soit 10 dans ce cas-ci, ce qui implique un nombre considérable de calculs. D’autre part, toutes ces comparaisons ne sont pas indépendantes puisqu’on devra utiliser un même ensemble de données au niveau de plus d’une comparaison. Ceci pose un problème car le nombre de fausses alarmes (erreur a) s’accroît. En effet, si Pr(erreur α) = 5% pour une comparaison, la probabilité de commettre au moins une erreur a lorsque nous effectuons N = ![]() comparaisons devient 1 – ( 1 – α)N, soit 40% dans notre exemple! Ce taux est inadmissible, raison pour laquelle il nous faut un autre test quand le nombre de niveau p est supérieur à 2.
comparaisons devient 1 – ( 1 – α)N, soit 40% dans notre exemple! Ce taux est inadmissible, raison pour laquelle il nous faut un autre test quand le nombre de niveau p est supérieur à 2.
Section 2. Introduction à l’analyse de variance (ANOVA)
Lorsque nous avons à comparer les résultats pour un nombre de groupes p > 2, nous utilisons la technique d’analyse statistique connue sous le nom d’analyse de variance plutôt que des tests t multiples. Remarquez que l’ANOVA peut aussi être utilisée quand p = 2 puisque alors, elle retourne la même conclusion qu’un test t.
Les avantages de l’ANOVA sont multiples. Entre autre, l’ANOVA permet de contourner le problème d’erreur α gonflé car elle ne réalise qu’une seule comparaison. De plus, comme nous le verrons au cours 9, lorsque nous utilisons plus d’un facteur, l’ANOVA calcule aussi l’effet d’interaction souvent si important.
Au cœur du problème de la vérification d’hypothèses statistiques se trouve le fait qu’il est toujours possible d’attribuer à des variations aléatoires une partie des différences observées entre les moyennes des échantillons. Dans une expérience, toutes les sources incontrôlables de variabilité qui affectent la mesure constituent ce qu’il est convenu d’appeler l’erreur expérimentale.
L’une des sources les plus importantes de variabilité incontrôlable provient des différences individuelles. Une autre source d’erreur provient de l’erreur de mesure, une mauvaise lecture de l’instrument, une erreur de transcription, un arrondissement, etc. D’autre part, une situation expérimentale n’est jamais parfaitement identique d’un moment à l’autre, puisque le sujet perçoit les deux événements comme étant successifs (mémoire). Il est impossible de créer des situations expérimentales exactement identiques. De plus, ces sources d’erreurs ne sont pas systématiques, elles sont aléatoires et indépendantes des effets du traitement.
Supposons que nous ayons p groupes de n sujets assignés au hasard à un niveau du traitement A. Par exemple, le groupe 1 subira le niveau 1 du traitement A, le groupe 2 subira le niveau 2, etc.
|
Traitement A |
||||
|
Sujets |
niveau 1 |
niveau 2 |
… |
niveau p |
|
1 |
X11 |
X12 |
… |
X1p |
|
2 |
X21 |
X22 |
… |
X2p |
|
3 |
X31 |
X32 |
… |
X3p |
|
4 |
X41 |
X42 |
… |
X4p |
|
… |
… |
… |
… |
… |
|
n |
Xn1 |
Xn2 |
… |
Xnp |
|
moyenne |
1 |
2 |
… |
p |
Chaque moyenne individuelle ![]() i regroupe n observation, et la moyenne des moyennes,
i regroupe n observation, et la moyenne des moyennes, ![]() , qui est aussi la moyenne de toutes les données individuelles, regroupe p × n données.
, qui est aussi la moyenne de toutes les données individuelles, regroupe p × n données.
Dans ce tableau, toutes les sources de variabilité incontrôlables au niveau du groupe 1 (c. à d. la variance du groupe 1) contribuent à l’erreur expérimentale. La variance intra groupe 1 est donc un estimé de l’erreur expérimentale. La même chose est vraie pour les variance intra groupe 2, 3, …, p. Si l’erreur expérimentale est présente au niveau de chaque groupe, il est donc possible d’obtenir un estimé stable de l’erreur expérimentale en combinant ces divers estimés en un seul. Autrement dit, l’ensemble de la variance intra groupe constitue un estimé de la variance de l’erreur expérimental (variance des sujets, de l’instrument de mesure, etc.).
Simplement pour illustrer, nous avons rempli le tableau suivant avec des données fictives obtenues de 18 sujets, à raison de 6 sujets par groupe (n = 6) répartis sur trois groupes indépendants (p = 3). Comme on le voit ici, l’effet du traitement est important (au moins intuitivement). Le score augmente de 30 quand le sujet reçoit le niveau 2 du traitement par rapport au niveau 1, et de 30 encore au niveau 3 par rapport au niveau 2. Comme on le voit, la variance intra groupe 1 est faible (écart type d’environ 4.6). Cette variance ne peut être que le résultat de l’erreur expérimentale puisqu’en principe, tous les sujets sont semblables (tirés de la même population) et soumis aux même conditions expérimentales. Puisque les sujets sont assignés au hasard, on s’attend aux mêmes variations dans les performances pour les sujets du groupe 2 et du groupe 3 (dans notre exemple, la variabilité des groupes 2 et 3 est identique à celle du groupe 1).
|
Traitement A |
||||||
|
Sujets |
niveau 1 |
niveau 2 |
niveau 3 |
|||
|
1 |
31 |
59 |
99 |
|||
|
2 |
29 |
61 |
88 |
|||
|
3 |
35 |
69 |
89 |
|||
|
4 |
39 |
65 |
97 |
|||
|
5 |
41 |
71 |
98 |
|||
|
6 |
33 |
63 |
97 |
|||
|
moyenne |
34.66 |
64.66 |
94.66 |
|||
Par ailleurs, la variance intergroupe reflète la variabilité observée entre les moyennes des différents groupes expérimentaux. Si l’hypothèse nulle est vraie, c. à d. si les moyennes des populations d’où les échantillons ont été tirés au hasard sont égales, la variance intergroupe reflètera elle aussi uniquement l’erreur expérimentale.
Dans note exemple ci-haut, si le traitement n’avait eu aucun effet, la moyenne du groupe deux aurait dû être d’environ 34.66, à plus ou moins l’erreur expérimentale près (soit un écart type, 4.63). Comme on le voit, le résultat du groupe deux est nettement plus élevé, et si on calcule la variance des moyennes, on obtient une valeur nettement plus élevée que la variance intra groupe (dans notre exemple, l’écart type entre les trois moyennes est de 30, soit près de 7 fois plus élevée. Cette différence dans les variances intra groupe (intra-colonne, si je puis dire) et intergroupe (entre les colonnes) est la basse de l’analyse de variance.
Il faut bien comprendre qu’il ne s’agit pas d’un test des variances (malgré le nom de la technique) mais bien un test sur les moyennes, telles qu’elles varient d’une condition à l’autre. Si elles varient trop (le niveau de comparaison étant la variance dans les colonnes), on déclare que les moyennes ne peuvent pas être identiques.
Si l’hypothèse nulle (absence d’effet du traitement) est vraie, nous avons deux estimés de l’erreur expérimentale, soit la variance intergroupe et la variance intra groupe. En faisant le rapport de ces deux estimés, la valeur attendue devrait être près de 1.
![]()
Par contre, si l’hypothèse nulle est fausse, (si les moyennes diffèrent d’un traitement à l’autre), la variance intergroupe, en plus de refléter l’erreur expérimentale toujours présente, reflète aussi l’effet du traitement expérimental manipulé par le chercheur. Donc, si l’hypothèse nulle est fausse, la variance intergroupe reflète l’effet du traitement expérimental plus l’erreur expérimentale alors que la variance intra groupe ne reflète que l’erreur expérimentale. Ainsi,
![]()
Le rapport variance intergroupe / variance intra groupe est la base de l’ANOVA. L’idée donc est de diviser la variance totale observée dans les données brutes en diverses parties afin de vérifier l’hypothèse de différence entre les moyennes des groupes. Il est ensuite possible d’évaluer l’importance relative des variations résultant des différentes sources et de décider, selon des règles précises à montrer, si les variations sont plus grandes que celles attendues sous l’hypothèse nulle.
Section 3. Répartition de la somme des carrés et des degrés de liberté
Avant d’aller plus loin, il est important de préciser le vocabulaire usuellement utilisé dans les ANOVA, surtout que ce vocabulaire est en général ambigu. Les ANOVA sont très souvent utilisées, et le vocabulaire est devenu standard dans beaucoup d’articles scientifiques, malgré son imprécision.
3.1. Termes usuels

dans laquelle k indexe les sujets de 1 à n.
Carré moyen (CM, ou en anglais, MS, Mean square). Dans ce cas-ci, le mot moyen réfère à la somme des carrés SC divisée par le nombre de degrés de liberté. Une fois encore, le mot carré réfère au carré des écarts à la moyenne. Il serait donc plus exact de l’appeler Moyenne des Écarts au Carré (MEC). Une autre façon de voir le CM est de dire qu’il s’agit de la somme des carrés (la variance) pondérée par les degrés de liberté (puisque CM × dl = SC).
3.2. Répartition de la somme des carrés
Nous avons vu (cours 2) que la variance est additive lorsque nous additionnons deux échantillons indépendants. Cependant, dans le tableau de données ci-haut, nous n’additionnons pas des données, mais les regardons suivant deux angles : intra groupe et intergroupe. Pour cette raison (lorsque le traitement n’est pas efficace), la variance n’est pas additive (variance totale ≠ variance intra groupe + variance intergroupe) Par contre, une propriété très intéressante est que la SC l’est. L’argument est très similaire à celui que nous avons vu pour le test sur la variance, mais ici, il est étendu pour plusieurs groupes :
Dans la formule ci-haut, Xki dénote la donnée du sujet k dans la condition i, ![]() i dénote la moyenne du iième groupe, et
i dénote la moyenne du iième groupe, et ![]() la moyenne globale. On vérifie facilement que la distance entre le score d’un sujet et la moyenne globale est égale à l’écart de ce sujet par rapport à la moyenne de son groupe plus l’écart de son groupe par rapport à la moyenne globale. Ici, un écart peut être positif (si la première valeur excède la seconde) ou négatif. L’étape suivante consiste à faire la somme pour chaque sujet appartenant au groupe i :
la moyenne globale. On vérifie facilement que la distance entre le score d’un sujet et la moyenne globale est égale à l’écart de ce sujet par rapport à la moyenne de son groupe plus l’écart de son groupe par rapport à la moyenne globale. Ici, un écart peut être positif (si la première valeur excède la seconde) ou négatif. L’étape suivante consiste à faire la somme pour chaque sujet appartenant au groupe i :
On se rappelle, à la ligne 4 ci-haut, que la somme des écarts à la moyenne donne toujours zéro. En faisant la somme pour les p groupes, on obtient :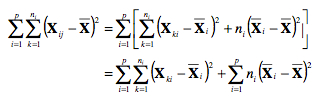
Comme on le voit dans l’équation, la sommes des écarts au carré est additive quand on regarde la SC totale (partie de gauche) et la SC intra groupe et intergroupe. On note généralement en abrégé :

où l’indice S|A indique le facteur sujet à l’intérieur d’un groupe donné, et A indique le facteur de traitement administré à nos sujets (soit le dosage dans l’exemple plus haut). Suivant cette relation, si la SC totale et la SC intra groupe sont connues, vous pouvez trouver la somme des carrés intergroupe.
En bref, la somme totale des carrés (SCT) de p groupes indépendants de n sujets chacun se décompose en deux parties indépendantes et additives : la somme des carrés intra groupes (SCS|A) et la somme des carrés intergroupe (SCA). Il est important de remarquer qu’en réalité, l’ANOVA ne divise pas la variance en partie additive. Il s’agit d’une méthode qui permet de diviser la somme des carrés en parties additives. Mentionnons que cette répartition de la SCT est valable pour un plan expérimental à groupes indépendants. Elle est aussi valide si les groupes ne contiennent pas un nombre égal de sujets.
Pour trouver les estimateurs de la variance, il ne reste plus qu’à trouver les degrés de liberté pour chacune de ces composantes.
3.3. Répartition des degrés de liberté
Le nombre total d’observations de p groupes indépendants de ni sujets chacun est ![]() Si les groupes ont un nombre égal de sujets (n), l’équation ci-haut est égale à p n. Le nombre de degrés de liberté (dl) total est p n – 1 puisque nous perdons un dl dans le calcul de la moyenne générale.
Si les groupes ont un nombre égal de sujets (n), l’équation ci-haut est égale à p n. Le nombre de degrés de liberté (dl) total est p n – 1 puisque nous perdons un dl dans le calcul de la moyenne générale.
Le nombre de dl associé à la SC intra groupe (SCS|A) est de (n1 – 1)+(n2 – 1)+ … (nk – 1). Nous perdons en fait un dl pour chaque moyenne utilisée, une par groupe. Ceci est égal à![]() – p = p n – p = p ( n – 1) si tous les groupes ont un nombre égal de sujets.
– p = p n – p = p ( n – 1) si tous les groupes ont un nombre égal de sujets.
Le nombre de dl associé à la SC intergroupe (SCA) est de p – 1. En effet, nous avons encore une fois besoin de la moyenne globale dans ce calcul. Il est facile de voir que :
pn−1= p(n−1)+(p−1) = pn − p + p −1
dlT =dlS|A +dlA
Donc, les dl d’un ensemble de p groupes indépendants se décomposent aussi en deux parties additives et indépendantes.
3.4. Non-répartition des carrés moyens
Si l’on divise les sommes des carrés par les degrés de libertés respectifs, on obtient les estimés de la variance correspondante, ce qui était le but initial. Par exemple, CM A = SCA / dlA . Il est à remarquer qu’à ce point-ci, les carrés moyens ne sont pas additifs : CMT ≠ CMS|A + CMA.
Section 4. Un exemple
Soit les données suivantes collectées sur 4 groupes de 8 sujets :
|
Traitement A : Groupe |
|||||
|
1 |
2 |
3 |
4 |
||
|
4 |
6 |
8 |
9 |
||
|
5 |
5 |
10 |
11 |
||
|
7 |
3 |
7 |
8 |
||
|
3 |
2 |
6 |
10 |
||
|
2 |
3 |
7 |
12 |
||
|
1 |
6 |
8 |
11 |
||
|
2 |
4 |
4 |
8 |
||
|
3 |
2 |
5 |
7 |
||
|
|
3.88 1.64 |
6.88 1.89 |
9.50 1.77 |
||
Dans cet exemple, ![]() = 5.91, et
= 5.91, et ![]() = 3.041 (il s’agit de l’écart type non biaisé). Toutes les moyennes et tous les écarts types s’obtiennent facilement avec une simple calculatrice ayant des fonctions statistiques. Pouvez-vous les retrouver? Ce sont tous ce dont nous avons besoin.
= 3.041 (il s’agit de l’écart type non biaisé). Toutes les moyennes et tous les écarts types s’obtiennent facilement avec une simple calculatrice ayant des fonctions statistiques. Pouvez-vous les retrouver? Ce sont tous ce dont nous avons besoin.
Les degrés de liberté sont respectivement 31, 4 × 7 = 28, et 3 pour SCT, SCS|A, et SCA.
Sachant que ![]() 2 = SCT / dlT , nous pouvons trouver SCT en mettant l’écart type au carré, puis en multipliant par les degrés de liberté total (p n – 1 = 31). On trouve 286.7. Pour calculer la somme des carrés intra groupe SCS|A, on peut utiliser le fait que la somme des carrés est additive aussi par groupe. La somme des carrés du groupe 1 est donnée par la relation
2 = SCT / dlT , nous pouvons trouver SCT en mettant l’écart type au carré, puis en multipliant par les degrés de liberté total (p n – 1 = 31). On trouve 286.7. Pour calculer la somme des carrés intra groupe SCS|A, on peut utiliser le fait que la somme des carrés est additive aussi par groupe. La somme des carrés du groupe 1 est donnée par la relation ![]() 21 = SCS|A1 / dlS|A1. On trouve alors pour le groupe 1, SCS|A1 = 25.8. De même pour les autres groupes : 18.8, 25.0, et 21.9. Le total est donc SCS|A = 91.5.
21 = SCS|A1 / dlS|A1. On trouve alors pour le groupe 1, SCS|A1 = 25.8. De même pour les autres groupes : 18.8, 25.0, et 21.9. Le total est donc SCS|A = 91.5.
Puisque la sommes des carrés est additive,
SCT = SCS|A + SCA
286.7 = 91.56 + SCA
=> SCA = 286.7 ‑ 91.5
SCA = 195.2
On peut facilement vérifier ce résultat en utilisant ![]() = 8 (3.38 – 5.91)2 + 8 (3.88 – 5.91)2 + 8 (6.88 – 5.91)2 + 8 (9.50 – 5.91)2 = 194.8, ce qui est la même réponse, à l’arrondi près.
= 8 (3.38 – 5.91)2 + 8 (3.88 – 5.91)2 + 8 (6.88 – 5.91)2 + 8 (9.50 – 5.91)2 = 194.8, ce qui est la même réponse, à l’arrondi près.
Les carrés moyens sont alors donnés par :

À ce point-ci, il est important de ne pas perdre de vue notre objectif : nous voulons deux mesures de l’erreur expérimentale. Une première nous est donnée par la variance intra groupe. Cet estimé est calculé par ce qu’on appelle le CMS|A, et donne dans l’exemple la valeur 3.27. Le second estimé de l’erreur expérimentale est donné par un estimé de la variance intergroupe, qu’on appelle CMA dont la valeur dans l’exemple est de 65.07.
Comme on le voit, les deux valeurs semblent très dissemblables. En effet, l’estimé de la variance intergroupe est presque 20 fois supérieure à l’estimé de la variance intra groupe (exactement 19.9). Nous sommes loin d’obtenir un ratio proche de 1! Il est donc fort probable que cette divergence sera significative. Il reste à voir comment quantifier cette probabilité.
Section 5. Le test F
a.1. Postulats
Le test F est basé sur le postulat que les données brutes Xij sont normalement distribuées. Il s’agit d’un postulat fort, et le théorème central limite n’aide pas puisque le postulat porte sur les données brutes et non sur les moyennes des groupes. Encore une fois cependant, ce test semble « robuste » en ce sens que lorsque les données sont seulement approximativement normales et nombreuses, les conclusions du test restent valides. La valeur testée par l’hypothèse est le ratio entre deux sommes de carrés pondérés par leurs degrés de liberté respectif. Comme nous l’avons vu au cours 3, un tel ratio est distribué comme une variable aléatoire de type F. On peut donc évaluer la probabilité d’obtenir un ratio quelconque (tel 19.9 de l’exemple précédent).
a.2. Hypothèses et seuil
L’hypothèse nulle prédit que le traitement n’a aucun effet. Donc, les différents groupes ont un résultat identique, nonobstant l’erreur expérimentale. Nous pouvons alors écrire :
H0 : μ1 =μ2 =…=μp
H1: il existe un μi ≠μj
Autrement dit, l’hypothèse nulle ne prédit aucune différence alors que l’hypothèse alternative prédit qu’au moins un groupe différera d’un autre groupe. L’ANOVA ne dit pas quels sont les groupes qui diffèrent cependant (nous verrons des techniques complémentaires au prochain cours). De plus, l’ANOVA est toujours un test unicaudal mais bidirectionnel. Nous adoptons dans cet exemple un seuil usuel de 5%.
a.3. Chercher le test
Le test F est de la forme :
Rejet de H0 si ![]()
où la valeur ![]() est distribuée comme un F(dlA, dlS|A). On utilise dans notre exemple ci-haut les degrés de liberté (3, 28) pour rechercher la valeur critique. Elle est, après inspection dans la table, s(a) = 2.947. On appelle souvent dlA le degré de liberté du numérateur et dlS|A, le degré de liberté du dénominateur pour des raisons évidentes.
est distribuée comme un F(dlA, dlS|A). On utilise dans notre exemple ci-haut les degrés de liberté (3, 28) pour rechercher la valeur critique. Elle est, après inspection dans la table, s(a) = 2.947. On appelle souvent dlA le degré de liberté du numérateur et dlS|A, le degré de liberté du dénominateur pour des raisons évidentes.
De plus, nous appelons souvent CMS|A le terme d’erreur. Ceci est moins évident, car en fait, les deux valeurs sont des estimées de l’erreur expérimentale. Cependant, seul le dénominateur est toujours un estimé de l’erreur expérimentale. Si l’hypothèse nulle était fausse, le numérateur représenterait l’erreur et l’effet du traitement. Souvent, on verra dans les textes l’abréviation CMe pour représenter le terme d’erreur.
a.4. Appliquer le test et conclure
Nous trouvons :
![]() = 19.9
= 19.9
qui est supérieur à la valeur critique 2.947. On rejette donc l’hypothèse nulle. On conclue qu’il existe au moins une différence significative et [comme cette différence significative est nécessairement celle impliquant les deux moyennes extrêmes] que le traitement a affecté les sujets, le groupe 4 ayant une moyenne significativement supérieure à celle du groupe 1. [Note : il s’agit des groupes extrêmes. Puisqu’il existe au moins une différence, ces deux groupes sont sans ambiguïté différents. Il est possible qu’il existe d’autres différences, par exemple, le groupe 2 diffère peut-être significativement du groupe 4, mais l’ANOVA ne permet pas de conclure sur les autres différences.]
Les résultats d’une ANOVA sont souvent présentés dans un tableau de la forme suivante :

Dans l’exemple précédent, on aurait :

Exercices
1.Appliquer l’ANOVA à ces données à l’aide de SPSS:
|
Traitement A : Groupe |
||||||
|
1 |
2 |
3 |
4 |
5 |
||
|
2 |
5 |
7 |
3 |
6 |
||
|
4 |
4 |
1 |
0 |
2 |
||
|
9 |
1 |
1 |
0 |
1 |
||
|
2 |
7 |
4 |
3 |
4 |
||
|
3 |
4 |
2 |
7 |
1 |
||
|
2 |
12 |
1 |
1 |
6 |
||
|
9 |
1 |
4 |
3 |
3 |
||
|
5 |
2 |
1 |
1 |
11 |
||
2. Appliquer l’ANOVA à ces données ayant un nombre inégal de sujets à l’aide de SPSS:
|
Traitement A : Groupe |
|||||
|
1 |
2 |
3 |
4 |
||
|
3 |
7 |
3 |
10 |
||
|
2 |
8 |
2 |
12 |
||
|
4 |
4 |
1 |
8 |
||
|
3 |
10 |
2 |
5 |
||
|
1 |
6 |
4 |
12 |
||
|
5 |
2 |
10 |
|||
|
3 |
9 |
||||
|
1 |
|||||
3.Si nous mesurons un sujet à un niveau donné un grand nombre de fois (i. e. on réplique la mesure un grand nombre de fois), peut-on mettre dans le tableau des données brutes son score moyen sur l’ensemble des réplications? Si oui, quelles sont les conséquences sur les postulats à la base du test F?


Si vous remarquez des informations erronées ou manquantes, merci de le partager par les Commentaires.